上高中以来,学校一直订了一份「报纸」当作业用,叫《学英语》。最近做题时发现报纸与时俱进,多了几个二维码,分别是微信公众号还有「扫一扫 查答案」。
目标网站
通过二维码扫描出来的结果是上一期的答案。网页的地址长这样:
简直不要太直白。
首先在网站逛了一圈,PC 版风格看起来仍然是很老旧的那种;网站首页是有专门的答案分区,但是点进来的答案很少。显然,我所需要的答案没有文章列表,必须要经过扫描二维码拿到。
然后便是尝试改地址:稍稍增减 id 参数,可以看到最近发的文章:
发现只有几期的答案是连在一起的,其余的有很多这家报社的其他产品的内容。这些答案的排布也并不是那么有规律,比如下一个 id 的是上上期的答案。那么,只需要爬取附近的每个页面,然后把符合要求的找出来就行了。
开发环境
Google 提供了免费的 Jupyter Notebook 环境—— Colab,无需配置,开箱即用。进入 后创建一个新的 PYTHON3 笔记本。
或者,你也可以下载 ANACONDA 并安装。接着执行命令
$ pip install pipenv
$ pipenv shell
$ jupyter notebook这之后默认浏览器会打开本地的 Jupyter Notebook。
我们需要安装 requests_html 做爬虫。
requests-html 是基于现有的框架 PyQuery、Requests、lxml、beautifulsoup4 等库进行了二次封装,作者将 Requests 设计的简单强大的优点带到了该项目中。
!pip install requests_htmlJupyter Notebook 中,以 ! 开头的行会被解释成命令。
爬取和解析
这种 CMS 一般都没什么反爬措施,连 X5 浏览器 UA 都不需要伪造。所有网页的标题都是相同的,所以爬取每个页面内的标题就好。
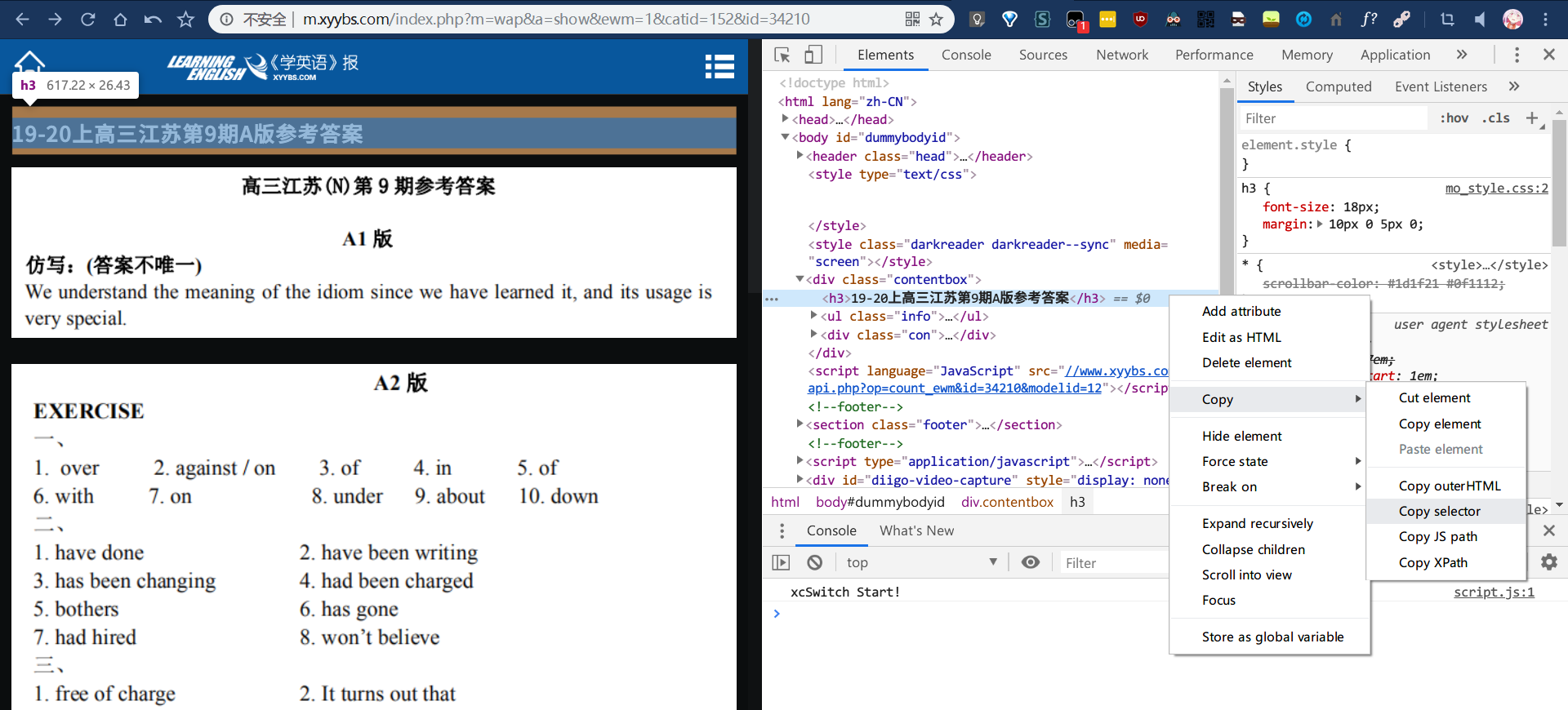
#dummybodyid > div.contentbox > h3对下面的答案图片如法炮制,它们的选择器分别是:
#dummybodyid > div.contentbox > div > p:nth-child(1) > img
#dummybodyid > div.contentbox > div > p:nth-child(2) > img
#dummybodyid > div.contentbox > div > p:nth-child(3) > img
#dummybodyid > div.contentbox > div > p:nth-child(4) > img页面最后一般会有 doc 文档可以下载,但是最近没有了。
然后便是遍历每个页面了。
{'34210': '19-20上高三江苏第9期A版参考答案', '34211': '19-20上高三江苏第8期A版参考答案', '34212': '19-20上八年级★云南第10期听力录音', '34213': '19-20上八年级邵阳第10期听力录音', '34214': "悦听悦读 The world's first artificial moon", '34215': '悦听悦读Superheroes from Asia', '34216': '19-20上八年级广东第10期听力录音', '34217': '19-20上外研八年级嘉兴第9期听力录音', '34218': '19-20上外研八年级嘉兴第10期听力录音', '34219': '19-20上外研八年级嘉兴第11期听力录音', '34220': '19-20上外研八年级嘉兴第12期听力录音', '34221': '19-20上八年级★赤峰第1期听力录音',
…,(省略一部分)
'34966': '19-20上九年级宁波期末检测一本通综合测评(五)听力录音', '34967': '悦听悦读Real-life Dora', '34968': '19-20上高三江苏第14期A版参考答案', '34969': '19-20上高三江苏(N)第15期听力录音', '34970': '19-20上高三江苏(N)第14期B1-B4版参考答案', '34971': '19-20上高一第24期A4版听力练习录音', '34972': '19-20上高三江苏第15期A版参考答案', '34973': '19-20上高三江苏(N)第16期听力录音', '34974': '19-20上高三江苏(N)第15期B1-B4版参考答案', '34975': 'Jane and Sara want to go skating(I)', '34976': 'Jane and Sara want to go skating(II)', '34977': '19-20上八年级(J)第17期听力录音', '34978': '19-20上八年级(J)第18期听力录音', '34979': '19-20上八年级(J)第19期听力录音', '34980': '19-20上八年级(J)第20期听力录音', '34981': '悦听悦读 An ancient Chinese story', '34982': '悦听悦读 Empty-City Strategy', '34983': '悦听悦读Hearing loss, a major problem for teenagers', '34984': '悦听悦读FOLLOW ME: Hearing loss, a major problem for teenagers', '34985': '故事乐园 The ice cream', '34986': "故事乐园 It's Mr Green", '34987': '悦听悦读A special fashion show', '34988': '悦听悦读Two cute girls', '34989': '19-20上八年级曲靖第15期听力录音', '34990': '19-20上七年级★福建第15期听力录音', '34991': '悦听悦读 Max Einstein: The Genius Experiment', '34992': '19-20上九年级(XJ)第9期听力录音', '34993': '19-20上九年级(XJ)第10期听力录音', '34994': '19-20上九年级(XJ)第11期听力录音', '34995': '19-20上九年级(XJ)第12期听力录音', '34996': '19-20上七年级★福建第16期听力录音', '34997': 'Bill and Kitty', '34998': '19-20上八年级曲靖第16期听力录音', '34999': '悦听悦读Flying car'}Demo
版权许可
- 本作品采用知识共享 署名—非商业性使用 4.0 国际许可协议(CC BY-NC 4.0 International)许可,阁下可自由地共享(复制、发行)和演绎(修改、转换或二次创作)这一作品,唯须遵守许可协议条款。
评论